USENIX Security 2023
Gradient Obfuscation Gives a False Sense of Security in Federated Learning
Kai Yue, Richeng Jin, Chau-Wai Wong, Dror Baron, and Huaiyu Dai
NC State University
Abstract
Federated learning has been proposed as a privacy-preserving machine learning framework that enables multiple clients to collaborate without sharing raw data. However, client privacy protection is not guaranteed by design in this framework. Prior work has shown that the gradient sharing strategies in federated learning can be vulnerable to data reconstruction attacks. In practice, though, clients may not transmit raw gradients considering the high communication cost or due to privacy enhancement requirements. Empirical studies have demonstrated that gradient obfuscation, including intentional obfuscation via gradient noise injection and unintentional obfuscation via gradient compression, can provide more privacy protection against reconstruction attacks. In this work, we present a new reconstruction attack framework targeting the image classification task in federated learning. We show how commonly adopted gradient postprocessing procedures, such as gradient quantization, gradient sparsification, and gradient perturbation may give a false sense of security in federated learning. Contrary to prior studies, we argue that privacy enhancement should not be treated as a byproduct of gradient compression. Additionally, we design a new method under the proposed framework to reconstruct images at the semantic level. We quantify the semantic privacy leakage and compare it with conventional image similarity scores. Our comparisons challenge the image data leakage evaluation schemes in the literature. The results emphasize the importance of revisiting and redesigning the privacy protection mechanisms for client data in existing federated learning algorithms.
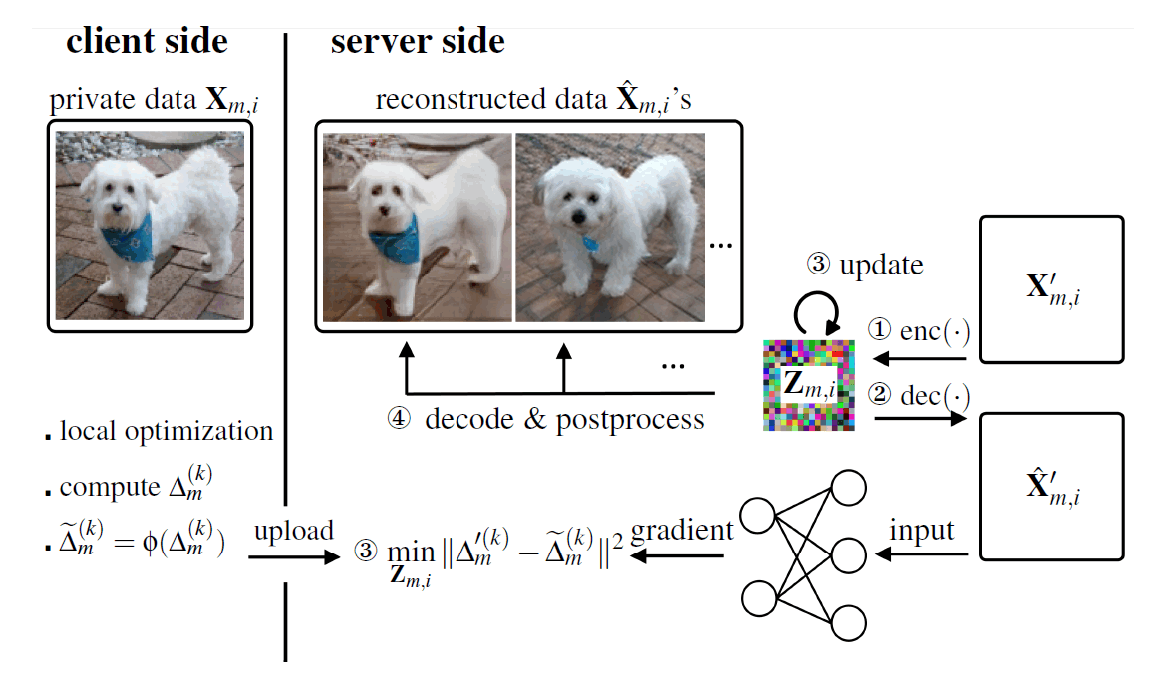
Fig 1. Schematic of the proposed attack method. The attacker first encodes an initial image into a low-dimensional representation to reduce the number of unknowns. Second, the attacker calculates the gradient by decoding the representation to an image and feeding it to the target neural network model. Third, the representation is updated by solving an optimization problem to minimize the discrepancy between the dummy gradient and client gradient. The final reconstruction results are obtained via decoding and postprocessing. Reconstructions can be different based on different postprocessing tools or optimization procedures.
Results


Fig 2. Reconstructed images from signSGD. Despite the loss of magnitude information caused by 1-bit quantization, ROG can reconstruct results visually similar to the raw images.
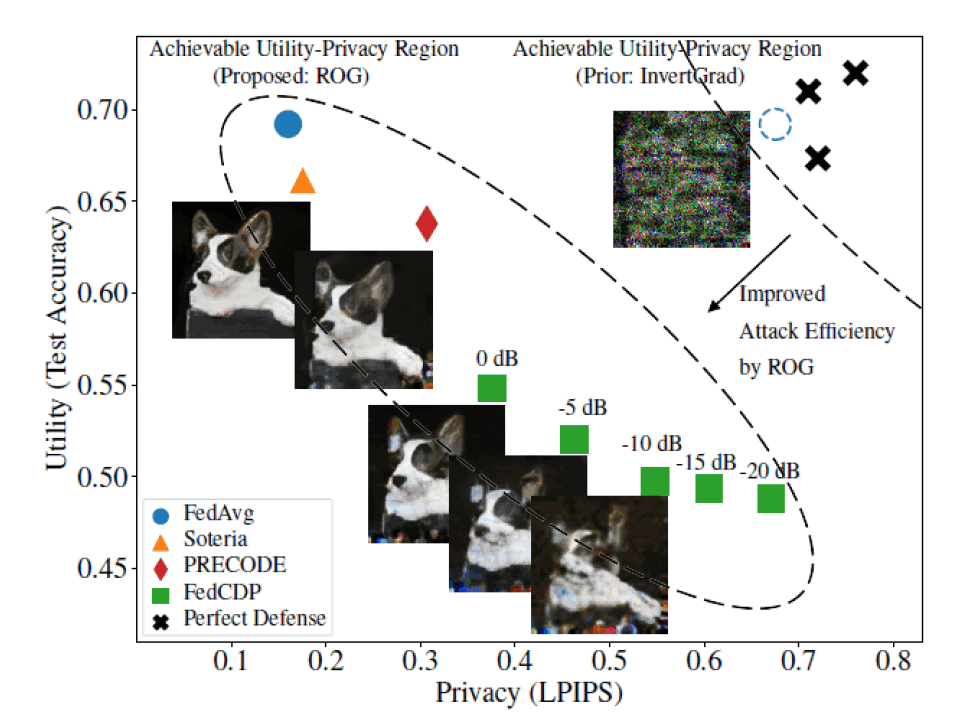
Fig 3. Trade-off between model accuracy and privacy under the ROG attack. A larger LPIPS value indicates better privacy protection against the attack. The cross points in the upper-right corner represent the desired/unrealistic defense schemes achieving high model accuracy and privacy protection. The dashed circle denotes the operating point of FedAvg under InvertGrad attack, which is misleadingly classified to the same region as the desired defense schemes and gives a false sense of security. Meanwhile, the three defense schemes have been verified to be effective against the InvertGrad attack, which may also be classified as desired defense schemes. The achievable utility--privacy region is shifted to the bottom left due to the proposed ROG attack.
Citation
title={Gradient Obfuscation Gives a False Sense of Security in Federated Learning},
author={Yue, Kai and Jin, Richeng and Wong, Chau-Wai and Baron, Dror and Dai, Huaiyu},
booktitle={USENIX Security Symposium},,
year={2023}
}